前言
MySQL 数据库承载了掌门绝大部分核心业务的数据存储,因此 MySQL 数据库的稳定运行至关重要。DBA 团队一直致力于保障数据库环境的平稳运行,编写有掌门 MySQL 数据库规范文档,也提供有掌门数据库查询上线运维平台。
规范虽然很全面,但是如果不了解数据库原理,不知道规范带来的效率提升,开发人员并不一定会严格遵守,规范也就失去了意义。
本篇文章旨在从数据库原理出发,从三个角度(建表、索引、SQL 语句)进行深入分析,在了解数据库底层原理的基础上,理解数据库规范、以及数据库优化方法。
一、建表
如果把 MySQL 数据库实例看作是一个图书馆,数据表就可以看作一本本的书。书名如同表名,概述用途,需要取的易懂且有意义;书本内容过多会选择分册发行,数据表也可以选择分表或者分区。
开发人员需要根据实际的业务场景、数据量大小设计不同的表,来满足业务需求。关系型数据库的数据字段后续更改代价较高,因此需要在前期设计阶段就需要考虑用途并设计合理的表结构。优秀的表结构设计,是数据库优化中非常重要的一环。数据表设计需要遵循以下规范要求:
1.字符集
规范:
数据库表字符集统一设置为
utf8mb4,排序规则为utf8mb4_general_ci。由于 DBA 已统一按照字符集 utf8mb4 ,排序规则 utf8mb4_general 创建数据库,因此表和字段的字符集可以不再额外设置,保持默认与数据库配置相同即可。
解析:
- 当字符集或者排序规则不一致时,会导致表无法关联查询
- 如果进行字符转换,会导致索引失效,而且也会额外消耗数据库性能
- 统一的字符集和排序规则设置,能减少不必要的字符集问题
CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci2.主键ID
规范:
必须创建无符号(
unsigned)自增(auto_increment)整形(int或bigint)主键 ID 字段
解析:
- 自增主键非常适合 MySQL 数据库聚簇索引数据结构
Int类型长度为 4 字节,bigint为 8 字节,数据长度较小,较小的字符类型可减少主键长度(后续在索引章节详解)- 无符号相比默认有符号数据量存储可大一倍,无符号 int 类型可存放 42 亿行数据,足够掌门一般应用所需
id int unsigned not null auto_increment comment 'ID主键’,
primary key(id),3.必含列
规范:
必须包含
deleted,create_time,update_time数据列
解析:
- 掌门数据系统禁止物理删除,应采用逻辑删除方式,并且在代码层维护标记 deleted 字段
- create_time 取记录创建时间,update_time 取记录更新时间,并由数据库自动维护
- 创建 create_time,update_time 列索引,以便进行查询
- 按此规范设计的表,极大的方便BI部门进行增量数据同步,减少同步任务的数据量
deleted tinyint not null DEFAULT 0 COMMENT '是否删除 0 未删除 1 删除 默认是0’,
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间,默认当前时间’,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间,默认当前时间’,
index idx_create_time(create_time),
index idx_update_time(update_time),4.大字段
规范:
尽量不要使用
blog和text等大字段
解析:
- 存储时:
实际数据存储在外部存储中,数据列上只存储大字段指针,指向外部存储。大字段在存储时需花费额外 IO 存储实际数据。 - 查询时:
如果列中包含 blog 和 text 列,查询时尽量不要查询该列,不要使用 select * 查询数据
查询大字段时需要通过指针找到外部存储,然后再读取字段内容。需要花费额外 IO 读取实际数据。
读取的大字段数据只能存放在磁盘中进行后续操作,效率低下。
5.行长度,页长度
规范:
MySQL 定义行长度不能超过
64KB(不包含 blog , text 类型)
页长度默认为16KB(由参数 innodb_page_size 定义)
解析:
- 所有列长度总定义不能超过 64KB ,超过后将无法添加新列
- 当行长度增加,会导致单个页存放的数据行数减少,检索数据需要消耗更多磁盘 IO
备注:基于以上行长度和页长度的定义,也许有小伙伴会有疑问,如果表真的存放了 64KB 数据,那岂不是一行数据会占用四个数据页,一个数据页中只能存放一行数据(或一行数据的一部分)。那么此时 MySQL 的 B+ 树的数据存储结构就退变为线性了,这是 MySQL 设计中绝对不允许的!!!
按照 MySQL 的 B+ 树设计,一个数据页中至少要存放两行数据,否则 B+ 树会从树状结构退化为线性结构。
因此当行存储的实际数据过大,在页中存放不下时,MySQL 在存储这行记录的时候,会将较大的数据列的数据存放在外部存储页中,数据页只保存指向外部存储页的指针。此时如果存储读取这个大的数据列,会额外消耗更多的 IO
6.字段类型
规范:
根据字段存储内容定义适当的字段类型
解析:
- 时间类型使用
date、datetime或者timestamp,不要使用 varchar 或者 int - ID 类型尽量使用 tinyint、smallint、int、bigint,不要使用 varchar
- 定长字符串尽量使用
char,不要使用 varchar(注意 char 最大定义为 255 ) - 字段尽量设置为非空(
not null),并设置 default 属性 - varchar 类型按需定义长度,不要定义过长。
5.1. 字段过长会导致索引长度过长,超过一定长度只能创建前缀索引,而前缀索引不能走到索引覆盖
5.2. 数据读取到内存中是按照定义长度存放,过长的定义会占用更多内存空间
7.字段长度
规范:
不同字段类型占用的数据存储空间不同,应尽量控制字段在满足业务场景可用的前提下,长度越短越好
解析:
- 如果字段可以为空,则需要 1 个字节存放字段是否为空标识
- 如果字段为 varchar 变长类型,当定义小于 255 字节时,需要 1 字节存放字段长度;当定义超过 255 字节时,需要 2 字节存放字段长度
- 常见字段类型的长度(以下字段长度均为不为空时的字段长度)
3.1tinyint1 字节;smallint2 字节;int4 字节;bigint8 字节;
3.2date3 字节;datetime8 字节;timestamp4 字节;
3.3 字符类型括号中定义的数字为字符数,即 varchar(32) 可以存放 32 个数字或者汉字
3.4 字符类型长度跟字符集有关(其中utf8占用 3 字节,utf8mb4占用 4 字节)
varchar(10) 类型(utf8mb4)字节数: 104B+1B=41B
varchar(100) 类型(utf8mb4)字节数:1004B+2B=402B
char(10) 类型(utf8mb4)字节数:10*4B=40B
二、索引
上文中把数据表比作是一本本的书,那么索引就是好比书本的目录。如果想要快速从书本中提取某项内容,那么查找目录必定是最快捷的。
MySQL 的索引是一把双刃剑,一方面能大幅提高查询速度,但同时索引也需要额外的存储,并且索引的维护是有代价的,每一行数据的增删改都需要维护索引信息,因此索引并不是多多益善,而应该按需创建合理的索引。
1.索引目的
建立索引的目的是为了减少扫描范围,提高查询速度。通过索引快速锁定数据范围,返回需要结果。一般情况下,如果单次扫描行数超过数据表总行数的一定比例(预估 10% 左右,官方并没有提供一个确定的数值),查询可能会放弃索引走全表扫描。因此必须要控制查询的数据范围,这也是我一直强调的,如果不能限制数据查询范围,那么所有的优化都是徒劳的。
由于数据增删改都会额外维护索引信息,索引过多会降低数据表的 DML 速度,因此只在经常查询并且选择性高的列上创建索引。
2.索引原理
通过索引(目录)方式,快速提取(查找)需要的记录。
MySQL 数据存放在磁盘上,索引结构为 B+ 树,索引即通过 B+ 树实现快速的从磁盘中读取所需要的数据(后面章节会详细介绍 B+ 树结构)
生活中随处可见索引的例子,如火车站的车次表、图书的目录、字典的查找等。它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,来提高检索效率。数据库索引也是类似的原理
3.索引长度
索引的长度决定不仅决定了索引占用的数据空间大小,也会影响查找数据的 IO 次数。
在同等数据量下,索引长度过长会导致单个数据页存放的索引条目数减少,索引高度增加,磁盘 IO 增加,并且索引占用空间增大。所以应该在满足要求的前提下,尽量减少索引长度。
索引的长度限制及计算方式如下:
- 索引最大长度为 767 字节,若索引长度超过 767 字节将无法创建(可考虑创建前缀索引)
- 索引长度与字段定义长度基本相同,前缀索引长度与定义的前缀长度有关
- 变长类型如 varchar,额外需要 2 个字节存放索引长度
- 如果字段可以为空,额外需要 1 个字节存放为空标识
- 索引长度 = 字段长度 + 是否为空(+1) + 是否变长(+2)
可通过执行 explain 查看执行计划,key 字段记录查询走哪个索引,key_len 记录所走索引的长度信息
mysql> explain select * from t1 where name like '张三%';
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| 1 | SIMPLE | t1 | range | uni_name | uni_name | 43 | NULL | 1 | Using index condition |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
1 row in set (0.05 sec)
mysql> show create table t1;
| Table | Create Table
| t1 | CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL,
`name` varchar(10) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`cnts` int(11) NOT NULL DEFAULT '1',
`a1` varchar(10) DEFAULT NULL,
`a2` int(11) DEFAULT NULL,
`a3` varchar(32) DEFAULT NULL,
`a4` varchar(32) NOT NULL DEFAULT '',
`a5` int(11) DEFAULT '1',
UNIQUE KEY `uni_name` (`name`),
KEY `idx_a2` (`a2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |如上表中,name 字段索引 uni_name 的 key_len 长度为 43 ,具体长度是按照以下方式计算规则:
索引长度 = 字段长度 + 是否为空(+1) + 是否变长(+2)
如 name 字段 varchar(10) 可以为空,字符集为 utf8mb4 ,则索引长度为: 10*4B+1B+2B=43B
而 a2 字段 int 可以为空,索引长度为:4B+1B=5B
4.聚集索引和非聚集索引
聚集索引
一个表只能有一个聚集索引,如果有主键列,则主键列为聚集索引;如果没有主键,有非空唯一列,则以第一个非空唯一列为聚集索引;否则数据库选择内部隐藏 6 字节的 ROWID 作为聚集索引。数据表的数据按照主键的顺序存放,因此对于 MySQL 顺序写入场景下,创建无意义的自增 ID 是最合适的。
聚簇索引:物理存储按照聚集索引列排序,聚集索引叶子节点 data 中存放完整行数据。
非聚集索引
一个表可以有多个非聚集索引,创建聚集索引只为提高查询效率。通过非聚集索引查找的是聚集索引指针信息,还需要通过回表方式查找具体的数据。所谓回表,是指通过普通索引获取到的聚集索引指针信息,再在聚集索引中执行一次 B+ 树查找,获取到最终的行数据。
非聚簇索引:非聚集索引列是逻辑排序,与实际数据的物理存储顺序不同。非聚集索引叶子节点 data 中存放聚集索引信息。
5.磁盘 IO 和预读
MySQL 的数据都是存储在磁盘上的,磁盘的查找方式是怎样的?查询速度怎样呢?如何才能快速的从磁盘中拿到所需要的数据。在介绍 B+ 树之前,我们先了解一下磁盘 IO 和预读机制。
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分:
- 寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在
5ms以下; - 旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘 7200 转,表示每分钟能转 7200 次,也就是说 1 秒钟能转 120 次,旋转延迟就是
1/120/2 = 4.17ms; - 传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在
零点几毫秒,相对于前两个时间可以忽略不计。
那么访问一次磁盘的时间,即一次磁盘 IO 的时间约等于 5+4.17 ≈ 9ms 左右,听起来还挺不错的,但要知道一台 500 -MIPS 的机器每秒可以执行 5 亿条指令,因为指令依靠的是电的性质,换句话说执行一次 IO 的时间可以执行 40 万条指令,数据库动辄十万百万乃至千万级数据,每次 9 毫秒的时间,显然是个灾难。
考虑到磁盘 IO 是非常高昂的操作,计算机操作系统做了一些优化,当一次 IO 时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内。局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次 IO 读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为 4k 或 8k ,也就是我们读取一页内的数据时候,实际上才发生了一次 IO,这个理论对于索引的数据结构设计非常有帮助。
6.B+树
了解完操作系统的磁盘 IO 和预读机制,我们知道磁盘 IO 是十分耗时的操作,并且一次 IO 拿到的并不是单条数据,而是预读到的操作系统 page 大小的数据( 4k或者8k )。
而 MySQL 数据库的 page 大小默认为 16k ,即一次 IO 预读 16k 的数据到数据库的 buffer pool 中。然后在内存中对数据进行过滤,内存中的数据过滤非常快,与磁盘 IO 时间相比时间可忽略不计。
那么好了,如何降低磁盘 IO 是数据库设计优化的重点。而 B+ 树就是为了降低磁盘 IO ,提高数据库查询效率而生。
备注:索引树的高度跟磁盘 IO 次数呈正相关,可简单理解为索引树高度即是磁盘 IO 次数。
谈到 B+ 树这个概念前,我们可以稍微了解一下二叉树、平衡二叉树、红黑树,B 树,这些树都有不同的数据结构,应用于不同的数据场景。MySQL 数据库选择 B+ 树作为数据存储结构,那么相比其他树,B+ 树有何优势呢?
备注:B+ 树是在 B 树上优化衍生而来,本章节我们主要谈谈 B+ 树与 B 树的区别及优势
- B 树的非叶子节点会存放数据,导致一个页存放的索引数较少,索引树较高
B+ 树的非叶子节点不会存放数据,只存放键值,一个页可以存放更多索引,索引树较矮 - B 树的查找可能会在非叶子节点命中,查找不稳定
B+ 树的查找必须到叶子节点才会命中,查找十分稳定 - B 树的范围遍历效率非常低
B+ 树的叶子节点中存放有双向指针构成一种链表结构,范围查询效率非常高效。而数据库的范围查询十分常见
因此 B+ 树更加适合作为 MySQL 数据库的数据存储结构,下图是一个 B+ 树的结构图
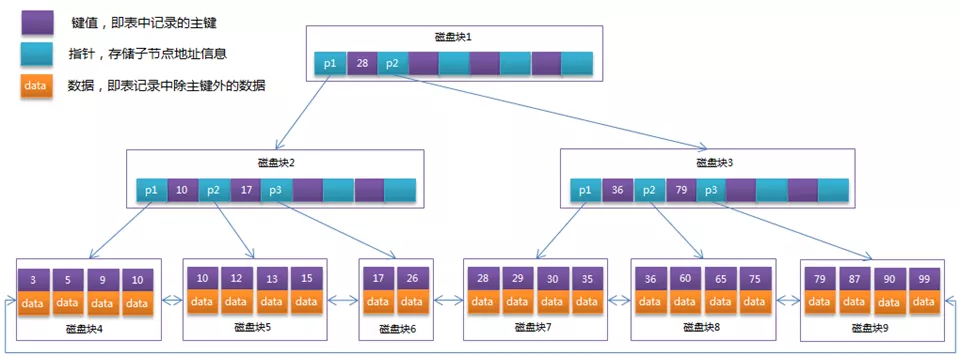
备注:在 MySQL 的 B+ 树结构中,聚簇索引和非聚簇索引存储稍有差异
聚簇索引的 data 部分,存储的是具体的行数据
非聚簇索引的 data 部分,存储的是主键 ID 信息
7.索引高度
既然磁盘 IO 是最影响性能的操作,那么优化的目的就是为了减少磁盘 IO 。而索引高度与磁盘 IO 是息息相关的,按照 MySQL 的索引设计,索引的高度就决定了磁盘 IO 的次数。那关于索引的高度,我们需要了解以下其计算规则

8.索引存储条目数
很多参考文档都会告诉你,索引的高度一般都在 3-4 层,但到底是 3 层还是 4 层呢?3 层索引和 4 层索引又能存放多少索引量,很多文档又会含糊描述的不清楚。此处我们根据实际例子,来看以下具体的索引能存储多少索引量
假设:表平均行长度为 300B,主键索引列 ID 为 int 类型
普通索引列 name 为 varchar(20) 类型非空 (utf8mb4)
普通索引列 info 为 varchar(150) 类型可以为空 (utf8mb4)
分别了解主键索引和普通索引在不同类型下的最大能存储条目数
主键索引的叶子节点中存放具体行数据;普通索引的叶子节点中存放主键信息
备注:索引存储中除索引信息外,还会用 4B 存储页号,6B 存储其他数据主键索引 ID(int),索引长度 4B
- 每个非叶子节点可存放 key 个数为 M1=16KB/(4B+4B+6B)≈1170
- 每个叶子节点可存放 key 个数为 M2=16KB/(300B+4B+6B) ≈52
- 则 3 层索引最终能存放最大条目数为:L=1170117052 ≈7118W
- 4 层索引最终能存放最大条目数为:L=117011701170*52 ≈832亿
普通索引 name(varchar(20)),非空,索引长度 20*4B+2B
- 每个非叶子节点可存放 key 个数为 M1=16KB/(20*4B+2B+4B+6B)≈178
- 每个叶子节点可存放 key 个数为 M2=16KB/(4B+20*4B+2B+4B+6B) ≈170
- 则 3 层索引最终能存放最大条目数为:L= 178178170 ≈538W
- 4 层索引最终能存放最大条目数为:L= 178178178*170 ≈9.58亿
普通索引 info(varchar(150)),可为空,索引长度 150*4B+2B+1B
- 每个非叶子节点可存放 key 个数为 M1=16KB/(150*4B+2B+1B+4B+6B)≈26
- 每个叶子节点可存放 key 个数为 M2=16KB/(150*4B+2B+1B+4B+6B+4B) ≈26
- 则 3 层索引最终能存放最大条目数为:L= 262626 ≈17576
- 4 层索引最终能存放最大条目数为:L= 262626*26 ≈456976
- 5 层索引最终能存放最大条目数为:L= 2626262626 ≈1188W
总结:
可以发现当索引长度增加时,会导致每个 page 页存放的索引数减少,索引高度增加。
特别是 char/varchar 类型,索引长度会因为 utf8mb4 字符集原因导致索引长度急剧增长,因此需要严格控制字段和索引长度。
9.索引优化
针对索引的优化,主要在于选择合适的列创建最优的索引,删除无效或者重复索引:
- 列的选择性越高,越适合创建索引。列的选择性计算 count(distinct coumn_name)/count(0)
- 选择性低的列上不要添加索引,如 bu,type,status,state,deleted 等列,索引列可能会导致查询效率下降
- 通过
Show index from table_name,查看表上的索引信息,cardinality 越大选择性越高 - 前缀索引。如果索引列太长,可考虑创建前缀索引
index idx_name(column_name(pre_len))达到 pre_len 的条数,如果达到总条数的 80% 即可
备注:前缀索引无法走索引覆盖
如 lessons 表的 les_uid 字段,定义为
les_uidvarchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
但是其实该字段存放的时 uuid 信息,长度为固定的 32 位,该字段如需创建索引,则可考虑前缀索引,指定前缀长度为 32index idx_les_uid(les_uid(32)),
- 组合索引。多列查询条件一起出现,可创建组合索引。并将经常查询列放前面,选择性高的放前面
如index(A,B,C)相当于建了 index(A,B,C),index(A,B),index(A) 三个索引
备注:组合索引的列数不宜过多,一般 2-3 列即可。列过多很难用到后面的列,且会增加索引长度。
如经常查询需要查询学生在某一个时间范围的上课信息,可创建基于 stu_id 和 les_start_time 的组合索引
index idx_stu_id_start_time(stu_id,les_start_time)
- 索引覆盖。当需要查询的列都在索引中,通过扫描索引即可获取所有信息。不需要回表操作,效率较高
mysql> explain select count(0) from students where stu_city='上海市';
+----+-------------+----------+------+---------------+--------------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+--------------+---------+-------+------+--------------------------+
| 1 | SIMPLE | students | ref | idx_stu_city | idx_stu_city | 767 | const | 2664 | Using where; Using index |
+----+-------------+----------+------+---------------+--------------+---------+-------+------+--------------------------+
1 row in set (0.06 sec)该查询统计行数信息,而 stu_city 列有索引,查询只需要使用 idx_stu_city 扫描即可取得 count 结果,无需回表取其他列数据。
extra 列的 using index 表明查询走索引覆盖
- 索引合并。在 MySQL 5.0 之前,一个表最多只能使用一个索引,从MySQL 5.1 开始引入索引合并(index_merge)技术优化,对同一个表可以使用多个索引分别进行条件扫描,然后将各自的结果进行合并(
intersect/union)。
备注:如果单列索引创建的不合理,比如在 bu、state、status 等列上创建单列索引,当 index_merge 使用到这些列做索引扫描合并,那么查询效率会非常低,需要关注!!!产生这种问题的主要原因是在选择性低的列上创建了索引,选择性低的列不适合创建索引,可能会降低查询效率!!!
index_merge之using union:
mysql> explain
select count(0)
from lessons
where stu_id=116401
or sel_id=1113;
+----+-------------+---------+-------------+----------------------------------------------------------------------------------------+-----------------------------------+---------+------+------+-------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------------+----------------------------------------------------------------------------------------+-----------------------------------+---------+------+------+-------------------------------------------------------------+
| 1 | SIMPLE | lessons | index_merge | lessons_stu_id,idx_stuid_lessub,IDX_LES_TYPE_STU_ID,stu_id_pay_type,idx_lessons_sel_id | lessons_stu_id,idx_lessons_sel_id | 4,5 | NULL | 1467 | Using union(lessons_stu_id,idx_lessons_sel_id); Using where |
+----+-------------+---------+-------------+----------------------------------------------------------------------------------------+-----------------------------------+---------+------+------+-------------------------------------------------------------+
1 row in set (0.09 sec)查询使用 or 连接多个条件,查询分别使用 stu_id 和 sel_id 列索引进行扫描,并将扫描结果进行取并集(union)
index_merge之using intersect:
mysql> explain
select count(0)
from lessons
where stu_id=116401
and sel_id=1113;
+----+-------------+---------+-------------+----------------------------------------------------------------------------------------+-----------------------------------+---------+------+------+------------------------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------------+----------------------------------------------------------------------------------------+-----------------------------------+---------+------+------+------------------------------------------------------------------------------+
| 1 | SIMPLE | lessons | index_merge | lessons_stu_id,idx_stuid_lessub,IDX_LES_TYPE_STU_ID,stu_id_pay_type,idx_lessons_sel_id | lessons_stu_id,idx_lessons_sel_id | 4,5 | NULL | 1 | Using intersect(lessons_stu_id,idx_lessons_sel_id); Using where; Using index |
+----+-------------+---------+-------------+----------------------------------------------------------------------------------------+-----------------------------------+---------+------+------+------------------------------------------------------------------------------+
1 row in set (0.07 sec)查询使用 and 连接多个条件,查询分别使用 stu_id 和 sel_id 列索引进行扫描,并将扫描结果进行取交集(intersect)
- 重复索引。重复的索引会需要更多的存储更见和维护代价,可考虑删除重复索引。
如索引index(A)和 index(A,B) 是重复的,重复的索引需要更多的存储空间和维护代价,可考虑删除 index(A)。
三、SQL语句
前面提到的建表和索引都是数据库优化中的基础,是非常关键的优化点,只有把基础打好,才能在此基础上做更深层次的优化。而 SQL 优化则是上层建筑,是查询的最终表现,通过 SQL 语句的执行计划、扫描行数、查询时间也能直观的反映出查询语句是否优秀。
SQL 语句的不同写法,对于底层数据的检索方式有着非常大的差异,也会影响查询方式和最终的数据结果。SQL 优化是在不改变结果的前提下,优化语句,降低扫描数据范围,达到缩短查询时间和扫描行数的目的。如果查询逻辑不合理,无法通过改写 SQL 达到优化的目的,那么则需要考虑调整查询逻辑。
1. 执行计划
SQL 语句的执行顺序真实的记录了解释器会如何一步步的执行语句,了解执行计划对于我们分析 SQL 语句,优化语句有非常大的作用
我们可以通过 explain + SQL 可以查看语句的执行计划。但是执行计划包含的内容太多,如果详细描述,又能整一篇文章了。因此本文只对我们比较关心的地方做重点叙述,简洁而又核心~
- Id:id 列数字越大越先执行,数字一样则从上而下执行
- Type:依次从好到差:
system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL,除了 all 之外,其他的 type 都可以使用到索引,如果 type 为 all 就需要关注并优化 SQL 了。 - Key:查询真正使用到的索引,select_type 为 index_merge 时,这里可能出现两个以上的索引,其他的 select_type 这里只会出现一个
Key_len:处理查询的索引长度,前文中已经介绍过 key_len 的计算规则。ICP 特性使用的索引不会计入- Rows:这里是执行计划中估算的扫描行数,不是精确值
- Extra:如果你想要优化你的查询,那就要注意 extra 辅助信息中的 using filesort 和 using temporary ,这两项非常消耗性能,需要注意。
2. 表关联
MySQL 数据表关联采用 Nested-Loop 方式,又名嵌套循环,是 MySQL 中最重要的表关联方式。在 Mysql 8.0 之前,也是仅有的一种表关联方式。想要优化查询语句,对于表关联方式必须要十分清楚。MySQL 在 Nested-Loop Join 的基础上,优化出 Block Nested-Loop Join 关联,两者比较类似。
2.1. Nested-Loop Join
一个简单的嵌套循环联接 (NLJ) 算法一次从循环中的第一个表读取一行,将每一行传递到一个嵌套循环,该循环处理联接中的下一个表。只要还有需要连接的表,这个过程就会重复多次。由于 NLJ 算法每次从外层循环传递一行数据到内存循环,因此循环会重复很多次。
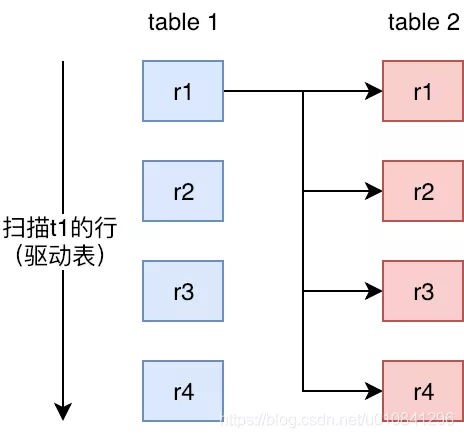
一个简单的 BLJ 算法执行过程如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}2.2. Block Nested-Loop Join
块嵌套循环 (BNL) 连接算法使用缓冲在外部循环中读取的行,以减少必须读取内部循环中的表的次数,(其中 join_buffer_size 参数决定每次读取并放入缓存中的数据量)。例如,如果将 10 行读入一个缓冲区并将该缓冲区传递给下一个内部循环,则可以将内部循环中读取的每一行与缓冲区中的所有 10 行进行比较。这可以将必须读取内部表的次数减少一个数量级。
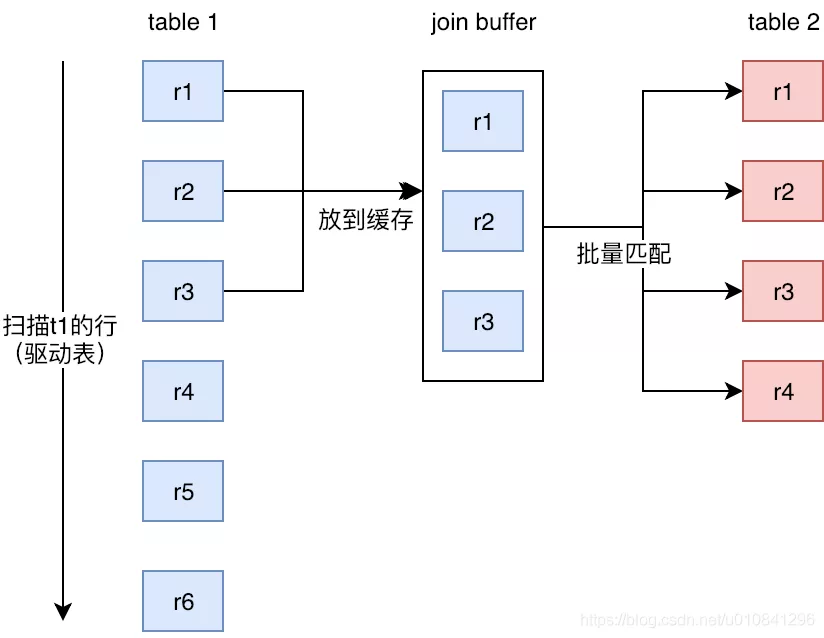
一个 BNL 算法执行过程如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}2.3.总结
不管是 NLJ 或者是优化后的 BNL 算法,都是从驱动表中筛选数据,与被驱动表进行匹配,有以下特性:
- MySQL 优化器会自动选择小表作为驱动表,以减少循环的次数。但并不会只以表大小作为唯一选择依据
- 最好不要干涉数据库的驱动表选择,让 MySQL 优化器自动选择最合适的表作为驱动表
- 查询会首先通过查询条件,过滤驱动表上的数据记录,筛选满足要求的结果放入缓存中。驱动表上需尽量通过索引扫描降低数据量。
- 被驱动表的关联字段上,需要有索引,否则每一次关联,被驱动表都要全表扫描,效率非常低。
- 被驱动表的字段类型、字符集、排序方式需和驱动表保持一致,否则无法直接关联
- 使用外关联时,只有基准表才能被选择为驱动表
如A LEFT JOIN B ON A.KEY=B.KEY,则只有 A 表才能被选择为驱动表,B 表不能作为驱动表
3. SQL 优化
SQL 优化的方式方法很多,此处罗列一些比较重要,容易出现问题的优化点:
- 尽量避免全表扫描,应考虑在
where和order by涉及的列上建立索引 - 被驱动表的关联字段需要创建索引,否则被驱动表会走全表扫描
- 索引遵循最左前缀匹配原则,
like写法只能将 % 放在右边,如 name like ‘掌门学员%’;若 % 放在左边会导致索引失效 - 应尽量避免在 where 子句中使用
!= , <> ,not in操作符,会导致索引失效 - 应尽量避免在 where 子句中使用 or 来连接条件,可尝试拆分为 union/union all
- 可考虑使用
join/left join关联查询,替代子查询、in/not in 的写法,尽量不要用子查询 - 如果 in 的内容是连续的,可使用
between…and或者 >….< 替代,改走范围扫描 - 不要在查询字段上使用函数或者表达式,会导致索引失效,可在参数字段上做函数或表达式运算
- 查询时需根据字段定义类型进行传参 ,若参数类型与字段定义类型不一致,会导致索引失效
- 不要使用
select *写法,只查询需要的列 - 不要在数据库中使用变量 + 分组排序方式构造排序字段,MySQL 需要基于全量数据做排序分组,效率很低
- 通过 limit 方式分页会导致后续分页越来越慢,可取前一次分页的最大 ID 作为下一页参数输入,进行分页
- 不要通过
order by rand()方式取随机数,效率极低。如果需要取随机数,可以先用随机数方法取得一个整数,然后根据 id>= 该整数即可。 - 禁止不必要的排序,排序操作极耗资源,不要轻易分组排序
- 不要在程序中使用
using index强制索引写法
4. SQL 优化示例
枯燥的知识点,哪有举个例子来的更清晰易懂,本章节我们用具体的例子讲述 SQL 优化的方法跟技巧。
4.1. 使用 union/union all 替换 or 写法
MySQL 的 or 写法,会导致查询索引失效,而更换为 union/union all 写法,虽然代码长度会增加,但是查询效率会有很大的提升
mysql> explain
select count(0)
from students
where students.created_at>='2021-05-01'
or students.referrer_user_id>0;
+----+-------------+----------+------+----------------------------+------+---------+------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+----------------------------+------+---------+------+----------+-------------+
| 1 | SIMPLE | students | ALL | created_at,idx_ref_user_id | NULL | NULL | NULL | 52833786 | Using where |
+----+-------------+----------+------+----------------------------+------+---------+------+----------+-------------+
1 row in set (0.06 sec)说明:students 表的 created_at 和 referrer_user_id 列都有索引,但是由于查询使用 or 连接,导致无法走索引扫描
type 为 all 说明查询走全表扫描,该查询 10min 仍然无法查询出结果
优化:
使用 union/union all 写法代替 or。鉴于 or 的关联记录可能存在重复,使用 union 写法,在外层对结果进行 count
mysql> explain
select count(0)
from
(select id
from students
where students.created_at>='2021-05-01'
union
select id
from students
where students.referrer_user_id>0) as t;
+------+--------------+------------+-------+-----------------+-----------------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+--------------+------------+-------+-----------------+-----------------+---------+------+---------+--------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 7638172 | NULL |
| 2 | DERIVED | students | range | created_at | created_at | 6 | NULL | 2085176 | Using where; Using index |
| 3 | UNION | students | range | idx_ref_user_id | idx_ref_user_id | 4 | NULL | 5552996 | Using where; Using index |
| NULL | UNION RESULT | <union2,3> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+------+--------------+------------+-------+-----------------+-----------------+---------+------+---------+--------------------------+
4 rows in set (0.24 sec)说明:改用 unio 后两个子查询中都能走各自对应的索引,并且因为是查询 ID 信息,查询走覆盖索引 using index,效率很高,该查询最终耗时 11.64s
4.2. 使用 join 关联替换子查询、in、exists 写法
子查询的写法虽然看起来直观清晰,但是子查询是一个独立的查询,不能参与到驱动表的数据过滤,而且子查询的结果数据会被放到临时表中存放,然后与驱动表进行关联,效率非常低。
在 Mysql 的写法中,非常不建议子查询写法,而应该尽量用 join 方式替换子查询写法。
mysql> explain
select sum(t.money)
from students
join
(select payments.stu_id,payments.money
from payments
where payments.is_paid=1
and payments.is_canceled=0
and payments.money>0) as t on students.id=t.stu_id
where students.created_at>='2021-05-01'
and students.created_at< '2021-06-01';
+----+-------------+------------+--------+-----------------------------------+---------+---------+----------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-----------------------------------+---------+---------+----------+---------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 2805183 | NULL |
| 1 | PRIMARY | students | eq_ref | PRIMARY,created_at | PRIMARY | 4 | t.stu_id | 1 | Using where |
| 2 | DERIVED | payments | ALL | IDX_MONEY_STU_ID,IDX_MONEY_SEL_ID | NULL | NULL | NULL | 5610366 | Using where |
+----+-------------+------------+--------+-----------------------------------+---------+---------+----------+---------+-------------+
3 rows in set (0.09 sec说明:payments 表使用单独的子查询,type 为 ALL 需要扫描整个 payments 表记录,将返回的结果存放在临时表,然后与 students 表进行匹配。查询耗时 22s
优化:
不使用子查询,直接使用 join 进行多表关联,并将查询条件写入到 where 中。
mysql> explain
select sum(payments.money)
from students
join payments on students.id=payments.stu_id
where payments.is_paid=1
and payments.is_canceled=0
and payments.money>0
and students.created_at>='2021-05-01'
and students.created_at< '2021-06-01';
+----+-------------+----------+-------+---------------------------------------------------+-----------------+---------+-------------------+---------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+-------+---------------------------------------------------+-----------------+---------+-------------------+---------+------------------------------------+
| 1 | SIMPLE | students | range | PRIMARY,created_at | created_at | 6 | NULL | 1983818 | Using where; Using index |
| 1 | SIMPLE | payments | ref | payments_stu_id,IDX_MONEY_STU_ID,IDX_MONEY_SEL_ID | payments_stu_id | 4 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+----------+-------+---------------------------------------------------+-----------------+---------+-------------------+---------+------------------------------------+
2 rows in set (0.26 sec)说明:不使用子查询,改为 join 写法后。查询首先根据 students.created_at 走索引扫描,然后根据查询的结果与 payments 表的 stu_id 进行关联。查询耗时 1.85s
4.3. 使用 join/left join 替代 in/exists、not in/not exists 写法
join 写法相当于做等值匹配,可以直接替代大部分场景的 exits 和 in 的写法
left join/right join 外关联的写法会以驱动表为母表,被驱动表只包含匹配的数据,配合在 where 条件中添加条件筛选,可用来替代 not exist 和 not in 写法
mysql> explain
select u.id
from users u
where u.updated_at > '2021-05-20 12:00:00'
and u.id not in(select a.user_id from users_account_number a);
+----+--------------------+-------+-----------------+----------------+----------------+---------+------+--------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+-------+-----------------+----------------+----------------+---------+------+--------+--------------------------+
| 1 | PRIMARY | u | range | idx_uptime | idx_uptime | 6 | NULL | 103664 | Using where; Using index |
| 2 | DEPENDENT SUBQUERY | a | unique_subquery | user_id_unique | user_id_unique | 4 | func | 1 | Using index |
+----+--------------------+-------+-----------------+----------------+----------------+---------+------+--------+--------------------------+
2 rows in set (0.06 sec)说明:查询是统计 users 表创建时间大于 ‘2021-05-20 12:00:00’,且不在 users_account_number 表中的用户 ID
请注意 id=2 的 select_typ 类型为 DEPENDENT SUBQUERY,表示外层 select 结果需要依赖于子查询的结果。效率会非常差
优化:
直接用 join/left join 的写法替代,效率将会有大幅提升
mysql> explain
select u.id
from users u
left join users_account_number a on u.id=a.user_id
where u.updated_at > '2021-05-20 12:00:00'
and a.user_id is null;
+----+-------------+-------+--------+----------------+----------------+---------+--------------+--------+--------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+----------------+----------------+---------+--------------+--------+--------------------------------------+
| 1 | SIMPLE | u | range | idx_uptime | idx_uptime | 6 | NULL | 105958 | Using where; Using index |
| 1 | SIMPLE | a | eq_ref | user_id_unique | user_id_unique | 4 | zm-user.u.id | 1 | Using where; Not exists; Using index |
+----+-------------+-------+--------+----------------+----------------+---------+--------------+--------+--------------------------------------+
2 rows in set (0.07 sec)说明:查询 select_type 都变为 simple ,并且查询先基于 updated_at 做索引过滤,然后与 users_account_number 进行匹配,效率非常高
4.4. 根据字段类型合理传参
在 MySQL 中,如果参数类型与字段定义类型不一致,会导致查询无法走到索引,这点需要关注。
mysql> explain
-> select *
from users
where mobile=13999999999;
+----+-------------+-------+------+---------------------+------+---------+------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------------+------+---------+------+----------+-------------+
| 1 | SIMPLE | users | ALL | users_mobile_unique | NULL | NULL | NULL | 83319185 | Using where |
+----+-------------+-------+------+---------------------+------+---------+------+----------+-------------+
1 row in set (0.08 sec)说明:users 表的 mobile 字段是 varchar 类型,并且创建有索引,但是输入参数是整形,导致查询无法走索引扫描,type 为 ALL 全表扫描。
优化:
根据字段类型进行合理的传参,如果 mobile 为 varchar 类型,则在参数上添加引号’’标识为字符类型
mysql> explain
-> select *
from users
where mobile='13999999999';
+----+-------------+-------+-------+---------------------+---------------------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------------+---------------------+---------+-------+------+-------+
| 1 | SIMPLE | users | const | users_mobile_unique | users_mobile_unique | 62 | const | 1 | NULL |
+----+-------------+-------+-------+---------------------+---------------------+---------+-------+------+-------+
1 row in set (0.07 sec)说明:mobile 字段为 varchar 类型,因此在参数上使用‘’标识为字符类型,查询走到 mobile 列的唯一索引,效率非常高。
4.5. 不要在查询字段上使用函数或表达式
如果在查询字段上使用函数或者表达式,MySQL 会首先对查询字段做函数运算,如果原本是准备基于该字段做索引匹配,函数运算会导致索引失效
mysql> explain
select count(0)
from students
join students_seller on students.id=students_seller.student_id
where date(students.created_at)='2021-05-05'
and students_seller.state=0;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
| 1 | SIMPLE | students | index | PRIMARY | created_at | 6 | NULL | 52853797 | Using where; Using index |
| 1 | SIMPLE | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
2 rows in set (0.09 sec)说明:由于在 students.created_at 字段上使用 date 函数,导致无法通过 created_at 列匹配满足时间要求的数据,通过 rows 列可以看到是全表扫描 5285w 数据量。
或许有人会疑问既然是全表扫描,为什么 type 是 index 而不是 ALL。这是因为 students 表只用到 created_at 和 id 列,这两列是直接包含在索引中的,查询是走的覆盖索引。
优化:
不要在查询字段上使用函数,如果需要使用函数,那么函数可以用在参数列上
mysql> explain
select count(0)
from students
join students_seller on students.id=students_seller.student_id
where students.created_at>='2021-05-05 00:00:00'
and students.created_at<='2021-05-05 23:59:59'
and students_seller.state=0;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
| 1 | SIMPLE | students | range | PRIMARY,created_at | created_at | 6 | NULL | 134092 | Using where; Using index |
| 1 | SIMPLE | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
2 rows in set (0.09 sec)说明:由于是查询注册时间为 2021-05-05 日的学生,那么可以替代为使用 created_at>= … and <= 的写法
优化后查询根据 students.created_at 走索引范围查询,匹配行数 rows 为 134092 条,然后与 students_seller 表关联,效率非常高。
4.6. 防止分页过大导致查询越来越慢,可使用id优化
在程序开发中,经常会对大量的返回结果进行分页返回展示,但是当分的页数过大,后续的分页查询会越来越慢,例如 limit 100 和limit 1000000,100 的查询效率差别很大。
mysql> explain
select students.id,students.user_id,students_seller.seller_id,students.stu_city
from students
join students_seller on students.id=students_seller.student_id
where students.created_at>='2021-01-01'
and students_seller.state=0
limit 100;
-- limit 1000000,100;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
| 1 | SIMPLE | students | range | PRIMARY,created_at | created_at | 6 | NULL | 23541528 | Using index condition |
| 1 | SIMPLE | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
2 rows in set (0.43 sec)说明:虽然 limit 100 和limit 1000000,100 的解释计划相同,但是执行时间差异非常大。
limit m,n 中的 m 数越大,则查询越慢。limit 100 的执行时间 0.05s;limit 1000000,100 的执行时间 35s
优化:
MySQL 更适合于精确查询,如果满足条件的结果很多,是不合理的,应该通过范围限制使得满足条件的结果足够小,最终结果应该控制在 1000 条、100 条甚至 10 条以内。
但是如果一定要对大量结果数据分页,那么可以考虑根据 ID 进行适当的范围限制
mysql> explain
select students.id,students.user_id,students_seller.seller_id,students.stu_city
from students
join students_seller on students.id=students_seller.student_id
where students.created_at>='2021-01-01'
and students_seller.state=0
and students.id>54978976 -- 取上一次分页的最大ID
limit 100;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
| 1 | SIMPLE | students | range | PRIMARY,created_at | PRIMARY | 4 | NULL | 26431416 | Using where |
| 1 | SIMPLE | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+----------+------------------------------------+
2 rows in set (0.09 sec)说明:例如假设第 10000 页取到的 100 行数据中最大的 students.ID 为 54978976,现在需要取得第 10001 页的 100 行数据
那么可以添加 students.id>54978976,然后取 100 行数据,此方法取得的即为第 10001 页的数据。
通过 id 字段的范围限制,比简单的 limit m,n 更加高效,即使是大的数据分页也不会导致效率变低。该方法执行时间稳定为 0.05s
4.7. where + order by + limit 查询陷阱
在程序设计中,经常需要用到 where+order by+limit 写法获取满足条件的、排序后的 N 条数据结果。这种写法本身并没有问题,但是在实际使用中,这条语句却常常引起严重的性能问题,需要我们重点关注。
mysql> explain
select students.id,students.user_id,students_seller.seller_id,students.stu_city
from students
join students_seller on students.id=students_seller.student_id
where students.created_at>='2021-04-05'
and students.created_at<='2021-04-05 23:59:59'
and students_seller.state=0
order by students.updated_at desc
limit 100;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+-------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+-------+------------------------------------+
| 1 | SIMPLE | students | index | PRIMARY,created_at | updated_at | 6 | NULL | 28608 | Using where |
| 1 | SIMPLE | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+-------+------------------------------------+
2 rows in set (0.08 sec)说明:查询是想取得学生注册时间在 2021-04-05 的,并且 state=0 的,按照更新时间取得最近 100 条学生记录。
请注意解释计划中得 key 为 updated_at 字段,我们明明是对 created_at 字段做范围限制,为啥 MySQL 选择走 updated_at 列索引?
敲黑板咯,拿出小本本~
当查询语句中包含 where+order by+limit 时
由于 MySQL 优化器会认为排序 order by 是非常耗时的操作,如果能在一开始就将结果做排序返回,那是最好的。而且 limit 100 会让优化器认为这 100 条记录是很容易满足的,此时优化器会走如下执行计划:
- 由于 students.updated_at 字段本身就有索引(已排序),按照 updated_at 字段每次取 100 条结果,然后走 where 匹配,将满足的结果返回
- 重复以上操作,直到有 100 条结果满足要求,循环结束
- 如果查询按照 students.updated_at 排序的数据经过 where 条件过滤后能快速满足 100 条结果输出,那么查询或许会非常快
- 但如果一致没有取到满足 where 条件的 100 条结果,会一直循环操作直至遍历 students 整个表!那这个代价是非常恐怖的
优化:
可以有很多办法避免以上执行计划与预想不一致的情况,本文列举两种办法:
方法1.
order by 的字段调整为与查询条件中的字段一致,但是可能造成结果并非原始期望结果,需要沟通业务部门是否能接受该 SQL 改造。(最优)
方法2.
将内部查询使用括号包裹,强制其作为一个先导执行的子查询,然后对子查询的最终结果集进行排序返回。由于子查询中会存放所有满足条件的结果,并且进行文件排序,如果满足条件的结果非常大,该方法会消耗较多资源效率较低。(亦可)
优化方案1:
mysql> explain
select students.id,students.user_id,students_seller.seller_id,students.stu_city
from students
join students_seller on students.id=students_seller.student_id
where students.created_at>='2021-04-05'
and students.created_at<='2021-04-05 23:59:59'
and students_seller.state=0
order by students.created_at desc
limit 100;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
| 1 | SIMPLE | students | range | PRIMARY,created_at | created_at | 6 | NULL | 184782 | Using index condition |
| 1 | SIMPLE | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
2 rows in set (0.09 sec)说明:排序字段修改为与查询字段一致即 students.created_at,由于索引查询本身就是排序的,不必再额外排序,效率非常高。
优化方案2:
mysql> explain
select t.*
from
(select students.id,students.user_id,students_seller.seller_id,students.stu_city,students.updated_at
from students
join students_seller on students.id=students_seller.student_id
where students.created_at>='2021-04-05'
and students.created_at<='2021-04-05 23:59:59'
and students_seller.state=0) as t
order by t.updated_at desc
limit 100;
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 184782 | Using filesort |
| 2 | DERIVED | students | range | PRIMARY,created_at | created_at | 6 | NULL | 184782 | Using index condition |
| 2 | DERIVED | students_seller | ref | student_id,idx_stu_sel_state | student_id | 5 | forge.students.id | 1 | Using index condition; Using where |
+----+-------------+-----------------+-------+------------------------------+------------+---------+-------------------+--------+------------------------------------+
3 rows in set (0.08 sec)说明:查询根据 created_at 字段检索满足条件的记录构建为子查询。外层查询结果对子查询进行排序然后取得 100 条记录。
此方法不会改变原始业务逻辑,如果满足条件结果集较小,效率很高;但是如果满足条件的中间结果集非常大,则查询效率也会较差
5.掌门慢SQL优化示例
上文中讲到的优化办法和优化示例,各位掌门人如能融会贯通,SQL 水平必定能更上一层楼。掌门生产环境中的 SQL 为满足业务功能,可能会关联较多的数据表,写的十分复杂,但是再复杂的查询,也是一个个的 Nested-Loop 关联。按照上述方法改写也能有优化效果,下面就是对掌门线上慢 SQL 的优化示例:
SQL1:数据仓库中优课 BU 的查询服务
mysql> EXPLAIN SELECT
count( 0 )
FROM
`uke_hours`.uke_retire_record rr
JOIN `uke_hours`.uke_apply_refund_info ari ON rr.apply_refund_id = ari.id
JOIN `uke`.uke_student stu ON rr.user_id = stu.user_id
LEFT JOIN `forge`.students students ON students.user_id = ari.stu_user_Id
JOIN `zm-user`.users users ON rr.user_id = users.id
LEFT JOIN `forge`.sellers se ON se.user_id = rr.handel_user
JOIN (
SELECT
ard.apply_refund_id
FROM
`uke_hours`.uke_apply_refund_detail ard,
`uke`.uke_class c
WHERE
ard.prod_id = c.prod_id
AND c.is_deleted = 0
GROUP BY
ard.apply_refund_id
) ard ON rr.apply_refund_id = ard.apply_refund_id
WHERE
rr.is_new_data = 1
AND (
rr.cc_id IN ( 1071853472 )
OR rr.cr_id IN ( 1071853472 )
OR rr.team_user_id IN ( 1071853472 )
OR rr.apply_user_id IN ( 1071853472 ));
+----+-------------+------------+--------+-----------------------------------------------------------------------+-----------------------------+---------+---------------------------+--------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-----------------------------------------------------------------------+-----------------------------+---------+---------------------------+--------+---------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 145787 | NULL |
| 1 | PRIMARY | rr | ref | idx_apply_refund_id,idx_user_id,idx_apply_user_id,idx_cc_id,idx_cr_id | idx_apply_refund_id | 8 | ard.apply_refund_id | 1 | Using where |
| 1 | PRIMARY | ari | eq_ref | PRIMARY | PRIMARY | 8 | ard.apply_refund_id | 1 | Using where |
| 1 | PRIMARY | se | eq_ref | sellers_user_id | sellers_user_id | 4 | uke_hours.rr.handel_user | 1 | Using where; Using index |
| 1 | PRIMARY | stu | ref | idx_userId_isDeleted_unique | idx_userId_isDeleted_unique | 8 | uke_hours.rr.user_id | 1 | Using index |
| 1 | PRIMARY | students | eq_ref | user_id | user_id | 4 | uke_hours.ari.stu_user_id | 1 | Using where; Using index |
| 1 | PRIMARY | users | eq_ref | PRIMARY | PRIMARY | 4 | uke_hours.rr.user_id | 1 | Using where; Using index |
| 2 | DERIVED | ard | ALL | idx_apply_refund_id,idx_prod_id | NULL | NULL | NULL | 145787 | Using temporary; Using filesort |
| 2 | DERIVED | c | ref | idx_prod_version | idx_prod_version | 130 | uke_hours.ard.prod_id | 1 | Using where |
+----+-------------+------------+--------+-----------------------------------------------------------------------+-----------------------------+---------+---------------------------+--------+---------------------------------+
9 rows in set (0.12 sec),实际执行时间 1.267s说明:该查询问题有二。
其一,查询中用到子查询,id=2 的 derived 子查询走 type=all 得全表扫描,且因为 group by 语句需要走文件排序操作
其二,查询条件使用到 or 条件,并且由于 or 的列太多,查询无法使用索引.只能基于 id=2 中子查询结果驱动整个查询
优化:
- 想办法用 join 方式将子查询部分改写,不要用子查询。
- or 条件中不应该传入 cc_id、cr_id、team_user_id、apply_user_id 多种筛选条件,而应该根据实际传参精确匹配列
- 可以将 or 条件改写为 union 写法
mysql> EXPLAIN SELECT
count( 0 )
FROM
`uke_hours`.uke_retire_record rr
JOIN `uke_hours`.uke_apply_refund_info ari ON rr.apply_refund_id = ari.id
JOIN `uke`.uke_student stu ON rr.user_id = stu.user_id
LEFT JOIN `forge`.students students ON students.user_id = ari.stu_user_Id
JOIN `zm-user`.users users ON rr.user_id = users.id
LEFT JOIN `forge`.sellers se ON se.user_id = rr.handel_user
JOIN `uke_hours`.uke_apply_refund_detail ard on rr.apply_refund_id = ard.apply_refund_id
join `uke`.uke_class c on ard.prod_id = c.prod_id
AND c.is_deleted = 0
WHERE
rr.is_new_data = 1
AND (
rr.cc_id IN ( 1071853472 )
OR rr.cr_id IN ( 1071853472 ) );
+----+-------------+----------+-------------+-----------------------------------------------------+-----------------------------+---------+------------------------------+------+-----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+-------------+-----------------------------------------------------+-----------------------------+---------+------------------------------+------+-----------------------------------------------+
| 1 | SIMPLE | rr | index_merge | idx_apply_refund_id,idx_user_id,idx_cc_id,idx_cr_id | idx_cc_id,idx_cr_id | 9,9 | NULL | 2 | Using union(idx_cc_id,idx_cr_id); Using where |
| 1 | SIMPLE | ari | eq_ref | PRIMARY | PRIMARY | 8 | uke_hours.rr.apply_refund_id | 1 | Using where |
| 1 | SIMPLE | se | eq_ref | sellers_user_id | sellers_user_id | 4 | uke_hours.rr.handel_user | 1 | Using where; Using index |
| 1 | SIMPLE | ard | ref | idx_apply_refund_id,idx_prod_id | idx_apply_refund_id | 8 | uke_hours.rr.apply_refund_id | 1 | NULL |
| 1 | SIMPLE | c | ref | idx_prod_version | idx_prod_version | 130 | uke_hours.ard.prod_id | 1 | Using where |
| 1 | SIMPLE | users | eq_ref | PRIMARY | PRIMARY | 4 | uke_hours.rr.user_id | 1 | Using where; Using index |
| 1 | SIMPLE | stu | ref | idx_userId_isDeleted_unique | idx_userId_isDeleted_unique | 8 | uke_hours.rr.user_id | 1 | Using index |
| 1 | SIMPLE | students | eq_ref | user_id | user_id | 4 | uke_hours.ari.stu_user_id | 1 | Using where; Using index |
+----+-------------+----------+-------------+-----------------------------------------------------+-----------------------------+---------+------------------------------+------+-----------------------------------------------+
8 rows in set (0.08 sec),实际执行时间 0.033s说明:改写后 where 查询中只保留 cc_id 和 cr_id ,由于都是 in 的等值查询,且列上均有索引条件,查询可以使用 index_merge 的优化特性,扫描行数为 2
并且查询将子查询写法替换为 join ,使得原本子查询中的全表扫描,变为普通的表关联,查询效率得到极大提升。优化效率 38 倍
SQL2:market_audit 数据库的查询服务
mysql> EXPLAIN
SELECT
ss.id,
ss.user_id userId,
ss.scan_state scanCode,
ss.bu,
ss.source
FROM
t_screenshot ss
LEFT JOIN t_screenshot_analyze sa ON ss.id = sa.screenshot_id
WHERE
ss.audit_state = 0
AND ss.re_upload_time IS NULL
AND ss.bu IN ( 3, 5, 4, 11, 12, 1, 2 )
AND ((
ss.re_apply_time IS NOT NULL
AND ss.re_apply_time >= '2021-05-14 11:30:00.145'
AND ss.re_apply_time <= '2021-05-21 10:30:00.145' )
OR ( ss.re_apply_time IS NULL
AND ss.upload_time >= '2021-05-14 11:30:00.145'
AND ss.upload_time <= '2021-05-21 10:30:00.145'
))
AND (
sa.poster_tag != 2
OR sa.poster_tag IS NULL);
+----+-------------+-------+--------+------------------------------------------------------+--------------------+---------+--------------------+---------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+------------------------------------------------------+--------------------+---------+--------------------+---------+------------------------------------+
| 1 | SIMPLE | ss | ref | idx_create_time,idx_re_upload_time,idx_re_apply_time | idx_re_upload_time | 6 | const | 1393993 | Using index condition; Using where |
| 1 | SIMPLE | sa | eq_ref | PRIMARY | PRIMARY | 8 | market_audit.ss.id | 1 | Using where |
+----+-------------+-------+--------+------------------------------------------------------+--------------------+---------+--------------------+---------+------------------------------------+
2 rows in set (0.07 sec)说明:看解释计划似乎查询是走到 type=ref 的非唯一索引扫描,实则查询只能根据 ss.re_upload_time IS NULL 这一个条件做简单的非空过滤
按照表数据的组成,无异于全表扫描。该查询执行时间 4.87s
优化:
查询中条件基本都无筛选性可言。可以用作筛选条件的就是 re_apply_time 和 upload_time ,但是这个条件在查询中使用 or 连接
需要用 union 代替 or 的写法,使查询能分别走到 re_apply_time 和 upload_time 列的索引。
mysql> EXPLAIN
SELECT
ss.id,
ss.user_id userId,
ss.scan_state scanCode,
ss.bu,
ss.source
FROM
t_screenshot ss
LEFT JOIN t_screenshot_analyze sa ON ss.id = sa.screenshot_id
WHERE
ss.audit_state = 0
AND ss.re_upload_time IS NULL
AND ss.bu IN ( 3, 5, 4, 11, 12, 1, 2 )
AND ss.re_apply_time IS NOT NULL
AND ss.re_apply_time >= '2021-05-14 11:30:00.145'
AND ss.re_apply_time <= '2021-05-21 10:30:00.145'
AND (
sa.poster_tag != 2
OR sa.poster_tag IS NULL)
union
SELECT
ss.id,
ss.user_id userId,
ss.scan_state scanCode,
ss.bu,
ss.source
FROM
t_screenshot ss
LEFT JOIN t_screenshot_analyze sa ON ss.id = sa.screenshot_id
WHERE
ss.audit_state = 0
AND ss.re_upload_time IS NULL
AND ss.bu IN ( 3, 5, 4, 11, 12, 1, 2 )
AND ss.re_apply_time IS NULL
AND ss.upload_time >= '2021-05-14 11:30:00.145'
AND ss.upload_time <= '2021-05-21 10:30:00.145'
AND (
sa.poster_tag != 2
OR sa.poster_tag IS NULL);
+------+--------------+------------+--------+------------------------------------------------------+-------------------+---------+--------------------+--------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+--------------+------------+--------+------------------------------------------------------+-------------------+---------+--------------------+--------+------------------------------------+
| 1 | PRIMARY | ss | range | idx_re_upload_time,idx_re_apply_time | idx_re_apply_time | 6 | NULL | 137 | Using index condition; Using where |
| 1 | PRIMARY | sa | eq_ref | PRIMARY | PRIMARY | 8 | market_audit.ss.id | 1 | Using where |
| 2 | UNION | ss | range | idx_create_time,idx_re_upload_time,idx_re_apply_time | idx_create_time | 5 | NULL | 178928 | Using index condition; Using where |
| 2 | UNION | sa | eq_ref | PRIMARY | PRIMARY | 8 | market_audit.ss.id | 1 | Using where |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+------+--------------+------------+--------+------------------------------------------------------+-------------------+---------+--------------------+--------+------------------------------------+
5 rows in set (0.20 sec)说明:将 or 连接的条件改为 union 连接,改写后语句长度增加一倍。
但是注意到 union 连接的两个子查询,都能根据对应的输入参数(upload_time 和 re_apply_time ),进行索引range扫描。
基于索引范围的扫描,效率提升很多。该查询执行时间为 0.245s,优化效率提升 20 倍
SQL3: forge 数据库的分页取数
mysql> explain
select
ss.student_id as studentId,
ss.pre_seller_id as preSellerId,
ss.state as state
from
students_seller ss force index(PRIMARY)
where
ss.bu = 0
and ss.seller_id is null
order by
ss.id asc
limit
115000, 5000;
+----+-------------+-------+-------+---------------+---------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+--------+-------------+
| 1 | SIMPLE | ss | index | NULL | PRIMARY | 4 | NULL | 120000 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+--------+-------------+
1 row in set (0.05 sec)说明:这条 SQL 的逻辑很简单,就是按照 bu=0 和 seller_id is null 作为条件,取得 students_seller 表所有满足条件的记录。
由于满足要求的记录较多,该查询可能会循环执行几百次。从慢 SQL 记录中可以看到 2021-05-21 日该查询执行了 721 次,总执行时长 11670s,总扫描行数 363 亿行,返回 360 万行
注意:limit 这种写法,解析行数会随着 limit m,n 后的 m 数增加导致解析行数持续增加,查询变慢。
优化:
针对这种循环取数,数据量很大的情况,需要根据 ID>last_max_id 的方式取数
如:上一次循环取到的students_seller表的最大id为102378346
mysql> explain
-> select
ss.student_id as studentId,
ss.pre_seller_id as preSellerId,
ss.state as state
from
students_seller ss force index(primary)
where
ss.bu = 0
and ss.seller_id is null
and id>=102378346
order by ss.id asc
limit 5000;
+----+-------------+-------+-------+---------------+---------+---------+------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+----------+-------------+
| 1 | SIMPLE | ss | range | PRIMARY | PRIMARY | 4 | NULL | 45237438 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+----------+-------------+
1 row in set (0.07 sec)说明:按照 id 范围限制后,每次查询时间均非常快速,效率很高。
按此方式优化后,每次查询时间稳定为 0.15s,全部扫描 721 次,总执行时长为 108.15s,效率提升 108 倍
结束语
MySQL 数据库博大精深,只有理解数据库底层原理,才能更好的做好优化工作。因此本文在介绍优化相关的规则和方法时,也会引申介绍相关数据库原理,也是希望帮助大家更好的理解并运用这些优化方法。
MySQL 是一个 OLTP 数据库,基于事务的增删改效率很高,基于索引的单值查询也非常快,MySQL 本身也非常适合这种短而快的数据操作或查询。
但是多表数据关联查询、查询返回大量数据结果,基于大量数据的统计或者排序操作,并不是 MySQL 数据库所擅长的。倘若不能减少数据扫描范围,那任何查询优化都是空谈。如果是这类 OLAP 数据需求,可以考虑一下其他架构设计,不能完全依赖 MySQL 数据库。